
 Magyar
Magyar  Český
Český  Polski
Polski ") Українська (Ukrainisch)
Українська (Ukrainisch)  Romanian
Romanian  Hrvatski
Hrvatski  Slovenský
Slovenský  Slovenščina
Slovenščina ") Српски (Serbisch)
Српски (Serbisch)  Italiano
Italiano  Nederlands
Nederlands ") עברית (Hebräisch)
עברית (Hebräisch)  Français
Français  Español
Español  English
English 
Beschreibung des Digitalisierung der Heirats-Register von Josef Heider für die Datenbanken des Vereins Familia Austria
verfasst von
Ing. Sepp Asanger
4040 Linz
Langfeldstraße 11
Diese E-Mail-Adresse ist vor Spambots geschützt! Zur Anzeige muss JavaScript eingeschaltet sein!

Buchscanner im Oberösterreichischen Landesarchiv Linz
- Allgemeines zum Projekt
- Übernahme der Heiratsregesten von J. Heider in die FA-Heiratsdatenbank
- Gesamtablauf der Digitalisierung der Heiratsregesten
- Digitalisierung der Heiderbücher am Buchscanner des OÖLA
- Nachbearbeitung der digitalisierten Buchseiten
- OCR-Schrifterkennung mit ABBYY FineReader
- Prüfung und Daten und Seitenformatierung mit einem Texteditor
- Zuordnung der Register-Daten zu Excel-Spalten
- Manuelle Prüfung durch Korrekturleser: Excel-Datei versus Bild-Dateien
- Verschmelzung (Verheiratung) der Paare auf eine Zeile
- Ergänzung der Heider-Hochzeitsdaten mit überregionalen Informationen
- Einspeisung in die DB
Allgemeines zum Projekt
Aufbau der Heider-Register
Voraussetzung für das Verständnis dieser Beschreibung ist die Kenntnis, wie die Heider-Register aufgebaut sind. Eine Beschreibung finden Sie unter Der Heider-Index. Persönliche Daten zum Autor des Index, Prof. Josef Heider, finden Sie unter Lebenslauf von Josef Karl Heider.
Gemeinsames Projekt von Familia Austria und dem Oberösterreichischen Landesarchiv (OÖLA)
2009 wurde die Idee geboren, die Heiratsbücher der Heider-Register zu digitalisieren und die Daten in die damals schon bestehende Hochzeitsdatenbank der Familia Austria einzuspeisen. Nach technischer Prüfung der Machbarkeit kam es 2010 zu einer vertraglichen Vereinbarung zwischen dem OÖLA und FA. Entsprechend dieser Vereinbarung darf FA die Bücher auf einem der Buchscanner des OÖLA kostenlos digitalisieren. Als Gegenleistung überlässt FA die maschinenlesbaren Daten dem OÖLA zur Verwendung in dessen lokalen Netzwerk.
Vorteile durch dieses Projekt
Gegenüber den physichen Heider-Büchern ergeben sich mit der Erfassung der Indexdaten in den Datenbanken von FA wesentliche Vorteile:
- Verfügbarkeit der Daten im Internet statt an den Lagerorten der Bücher im OÖLA bzw. in den Pfarren.
- Die Suche in den Datenbanken ist pfarrübergreifend. Personen werden daher auch dann gefunden, wenn sie in eine andere Pfarre geheiratet haben oder in eine andere Pfarre gezogen sind.
- Daten von anderen Quellen, so verhanden, werden ebenfalls gefunden.
- Vielfälige Suchmöglichkeiten mit der Möglichkeit von gezielten Eingrenzungen.
Datenaustausch mit den Projektbeteiligten
Zu Beginn des Projektes erfolgte der Datenaustausch über Stick oder CD. Durch die dramatisch gestiegenen Kapazitäten des www erfolgte der Datenaustausch aber bald über das Netzwerk, konkret über Dropbox. Die Bilder und die Textseiten sind auf Dropbox gespeichert, auf die die internen Projektmitarbeiter Zugriff haben. Bei Zuteilung eines Heider-Buches zur manuellen Prüfung an einen externen Mitarbeiter bekommt dieser einen Link zu den Scandateien der zu prüfenden Pfarre. Nach Abschluss der Prüfung und Einspeisung der Daten in die FA-Datenbank werden die nicht mehr benötigten Verzeichnisse mit ihren Dateien aus der Dropbox gelöscht.
Schreibweise von Namen und Orten
Ein Grundsatz ist, die Daten in der Originalform zu übernehmen. Dabei ergaben sich aber einige Schwierigkeiten. So hat J. Heider bereits viele Namen "standardisiert", d.h. veraltete Schreibweisen durch später üblichere ersetzt. Das erleichtert zwar das Suchen nach Namen in der Datenbank, die in der originalen Schreibweise sonst schwer zu finden wären, ist aber doch eine Verfälschung der Originalquelle. Andererseits hat Heider Ortsnamen in der Originalschreibweise übernommen, die oft sehr unterschiedlich vom Matrikelführer geschrieben wurden. In eindeutigen Fällen wurde im Hinblick auf die Datenbankabfrage der korrekte Name in die Datenbank übernommen.
Übernahme der Heiratsregesten von J. Heider in die FA-Heiratsdatenbank
Gesamtablauf der Digitalisierung der Heiratsregesten
Um die Daten der maschingeschriebenen Seiten der Heiratsbücher in die Heiratsdatenbank von FA zu übernehmen, sind eine Reihe von mehr oder minder aufwändigen Schritten notwendig. Besonderen Wert haben wir dabei auf größtmögliche Vermeidung von Fehlern gelegt.
Folgende Arbeitsschritte sind für den gesamten Ablauf erforderlich:
1. Digitalisieren der Heiderbücher im OÖLA
2. Nachbearbeiten der digitalisierten Bilder
3. OCR Schrifterkennung mit ABBYY Fine Reader und manuelle Korrekturen
4. Formatierung und Prüfung der Seiten mit speziellem Text-Editor und weitere Korrekturen
5. Zuordnung der Index-Daten zu Excel-Spalten
6. Manuelle Prüfung durch Korrekturleser: Excel-Datei versus Bild-Dateien
7. Verschmelzung (Verheiratung) der Paare auf 1 Zeile
8. Ergänzung der Heider-Hochzeitsdaten mit überregionalen Informationen
9. Einspeisung in die DB
Digitalisierung der Heiderbücher am Buchscanner des OÖLA
Das Einscannen der Heider-Bücher erfolgt auf Buchscannern des OÖLA. Das Einscannen sollte mit großer Sorgfalt erfolgen, um bei der späteren OCR Buchstabenerkennung eine hohe Erkennungsrate zu gewährleisten. Das dünne Papier neigt jedoch zur Faltenbildung und bei dicken Büchern entsteht eine Aufwölbung in der Buchmitte, die die Qualität des Scan-Vorganges durch Verzerrungen beeinträchtigen. Das Ergebnis des Scans wird am Bildschirm angezeigt. Häufig muss die Position des Buches oder die Seite nachjustiert und der Scan wiederholt werden. Erst wenn der Scan passt, wird die digitalisierte Seite auf einen Stick gespeichert.
Nachbearbeitung der digitalisierten Buchseiten
Das Bild (= Scan) einer Buchseite ist eine Datei, die mit einer automatischen Nummer (= Dateiname) versehen wird. Diese Nummer spiegelt nicht die Nummer der Heider-Buchseite und den Namen der Pfarre wider. Dies ist jedoch notwendig, um jederzeit schnell von einem Scan zur zugehörigen Seite des Heiderbuches zu finden. Es müssen daher alle Dateien umbenannt werden. Dabei sind Fehler in der Seitennummerierung, die in den Heiderbüchern passiert sind, zu berücksichtigen. Schiefe Seite führen bei der OCR Schrifterkennung am Zeilenbeginn zu unerwünschte Leerzeichen. Deshalb müssen die Bilder mit einem Bildbearbeitungsprogramm so ausgerichtet werden, dass die Zeilen vertikal genau untereinander stehen.
OCR-Schrifterkennung mit ABBYY FineReader
Die OCR-Schrifterkennung versucht, aus der Bilddatei (die digitalisierten Buchseiten sind computertechnisch nur Bilder) die Buchstaben zu erkennen und damit für den Computer lesbar zu machen. Aus den Bilddateien entstehen dadurch Textdateien, die die Grundlage für die weiteren Verarbeitungsschritte sind. Die Erkennungsquote der Texterkennung hängt wesentlich von der Schrift- und von der Scanqualität ab.
Das Ergebnis der Schrifterkennung muss manuell geprüft werden. Farbig unterlegte Zeichen sind ein Hinweis auf Unsicherheit in der Schrifterkennung und können schnell mit dem Original verglichen werden. Unbekannte Worte bzw. Begriffe werden rot unterstrichen und können so leicht auf Gültigkeit oder Fehler geprüft bzw. dem Wörterbuch hinzugefügt werden.
In dem gezeigten Beispiel sehen Sie viele blau unterlegte Zeichen. Viele davon sind jedoch richtig, andere werden durch nachfolgende Programme automatisch korrigiert (z.B. Interpunktionen beim Datum). Mehrfache Leerzeichen und typische Umwandlungsfehler, sozusagen chronische OCR-Fehler, wie z.B. Y, T, v, 7 statt V im tomus werden ebenfalls automatisch berichtigt. Die Spaltenüberschrift wird nicht gebraucht und daher zur Gänze gelöscht. So bleiben relativ wenige Zeichen übrig, die manuell korrigiert werden müssen.
Wenn nicht klar ist, wie der ursprüngliche Text im Scan aussieht, kann man das im unteren Teil des Fensters überprüfen. Als Beispiel sei auf das Wort Witwejf hingewiesen, das eigentlich, wie unten zu sehen, Witwe heißen sollte.

Nach erfolgter Korrektur wird die übersetzte Seite als Textdatei abgespeichert.
Prüfung und Daten und Seitenformatierung mit einem Texteditor
Beim Abspeichern der Textdatei wird ein programmierbarern Editor (KEDIT) gestartet und die Textseite angezeigt. Diese Seite wird nun einer Reihe von inhaltlichen und formalen Prüfungen unterzogen. So soll z.B. die Dateinummer mit der Seitennummer des Heiderbuches übereinstimmen, das Hochzeitsdatum aufsteigend sein, der Name in der ersten Zeile mit dem Buchstaben bzw. den Buchstaben der Indexgruppe beginnen, der tomus für das Indexbuch gültig, tomus und innerhalb desselben die pagina aufsteigend sein und die Texte sollen nicht in die Nachbarspalte hineinlaufen. Die Buchstaben o und l werdenn, wenn sie in Zahlen vorkommen, automatisch auf 0 und 1 umgewandelt, nach den Ziffern für Tag und Monat wird, was immer dort für ein Zeichen steht, durch einen Punkt gesetzt und das Datum auf Plausibilität geprüft. Diese und andere typischen OCR-Fehler werden, wie schon vorher erwähnt, automatisch korrigiert.
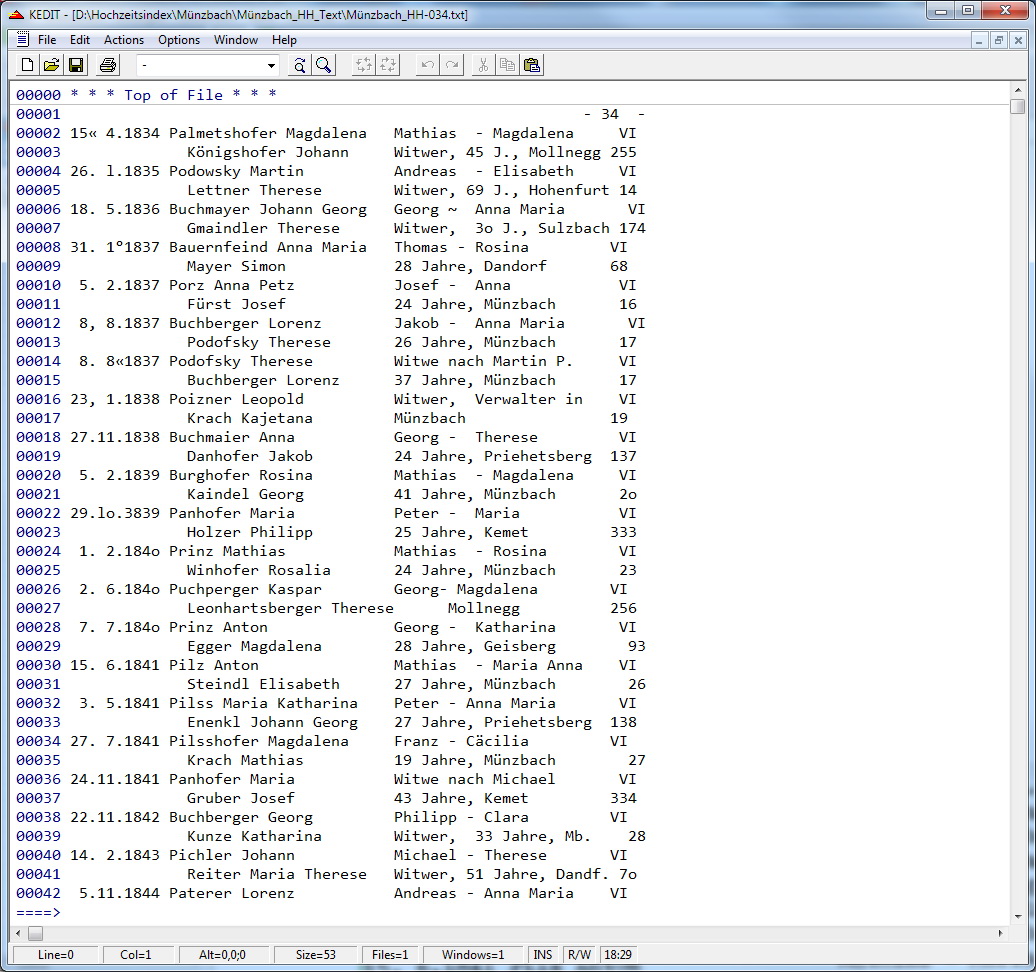
Diese Prüfungen erfolgen selbst entwickelten Prüfroutinen. Dabei mussten die vielen Varianten in den Indexseiten berücksichtigt werden, was einen erheblichen Programmieraufwand zur Folge hatte. Dieser Aufwand zog sich über viele Monate hin, weil beim Bearbeiten neuer Bücher immer wieder neue Varianten auftauchten, was entsprechende Anpassungen der Prüfroutinen erforderte. Der Aufwand hat sich jedoch sehr gelohnt, weil viele Ungereimtheiten entdeckt werden, die man bei einer manuellen Kontrolle durch die Eintönigkeit der Tätigkeit sehr leicht übersieht. Das folgende Beispiel veranschaulicht die Auswirkung dieser maschinellen Prüfung und Formatierung einer Buchseite.

In diesem Beispiel ist die pagina nicht aufsteigend, wie sie eigentlich sein sollte, sondern springt willkürlich hin und her. Der Grund dafür liegt darin, dass die Matriken im Heiratsbuch nach Ortschaften gegliedert wurden. Durch die Sortierung nach Buchstaben kommt es dann zu diesen wilden Sprüngen. Jede absteigende pagina führt in der Prüfroutine zu einer Nachricht und zu einer gelb markierten Zeile, wodurch die Seite sehr unübersichtlich wird. In diesen Fällen wird daher die Prüfung der pagina unterdrückt und die wirklichen Fehler kommen besser zur Geltung.
Zuordnung der Register-Daten zu Excel-Spalten
In obigem Beispiel ist die spaltenweise Aufteilung der Daten gut ersichtlich. Die Spalteneinteilung in der FA Hochzeitsdatenbank ist so gestaltet, dass sie alle möglichen Informationen einer Hochzeitseintragung aufnehmen kann, ist also viel umfangreicher. In diesem Arbeitsschritt geht es daher darum, die Informationen aus den Heider-Registern auf die korrespondierenden Spalten in der Hochzeitsdatenbank aufzuteilen. Das ist bei der Spalte Eltern, Beruf, Ort schwierig, weil selbst für den Leser diese Zuordnung nicht trivial ist. Auch hier war ein erheblicher Programmieraufwand und nachfolgende manuelle Bearbeitung notwendig, um die verschiedenen Elemente zu identifizieren und den richtigen Spalten zuzuordnen. In diesem Arbeitsschritt werden alle Dateien eines Registerbuches in eine einzige Excel-Datei zusammengefasst. Eine Excel-Datei entspricht somit einem Heider-Registerbuch.
Manuelle Prüfung durch Korrekturleser: Excel-Datei versus Bild-Dateien
Die im vorigen Kapitel beschriebene maschinelle Aufteilung der Daten in die Spalten der Datenbank führt manchmal zu Fehlern, weil es immer wieder Abweichungen vom allgemeinen Schema gibt. Auch die Umwandlung der Bilddaten in computerlesbare Schrift durch die OCR-Software ist fehleranfällig und trotz aller maschinellen und manuellen Prüfungen werden nicht alle Fehler entdeckt. Deshalb muss das bisherige Ergebnis manuell geprüft werden, indem jede Zeile in der Excel-Datei mit den Scans verglichen wird. Diese manuelle Prüfung erfolgt durch freiwillige externe Mitarbeiter, denen die notwendigen Daten und Anleitungen zur Verfügung gestellt werden. Nach der manuellen Prüfung kommt die korrigierte Excel-Datei wieder an das Team zur weitern Bearbeitung zurück.
Verschmelzung (Verheiratung) der Paare auf eine Zeile
Im Heider-Hochzeitsregister kommt jedes Brautpaar doppelt vor: Einmal unter dem Namen des Bräutigams mit seinen zusätzlichen Informationen und ein zweites Mal unter dem Namen der Braut mit ihren zusätzlichen Informationen. Diese Form ermöglicht in den Registerbüchern das Aufsuchen nach beiden Namen. In einer Datenbank erfolgt das Suchen mit entsprechenden Suchfunktionen über die gesamte oder auch nur Teile der Datenbank und nicht durch Blättern wie in einem Buch. Deshalb ist in der FA Hochzeitsdatenbank die Speicherform anders strukturiert: Es gibt für jedes Brautpaar grundsätzlich nur eine einzige "Zeile" mit allen relevanten Informationen von Braut und Bräutigam. Vor der Einspeisung der Hochzeitsdaten in die Datenbank müssen daher alle zu einem Brautpaar gehörigen Zeilen des Heider-Index zu einer einzigen Eintragung zusammengeführt werden. Diesen Vorgang nennen wir sinniger Weise "Verheiraten".
Diese Zusammenführung der Brautpaare erfolgt, wie schon frühere Prüfungen und Arbeitsschritte, maschinell mit selbst entwickelten Programmen. Dabei können wieder verschiedene Probleme auftreten und auch Fehler entdeckt und berichtigt werden. Beispielsweise sollten das Hochzeitsdatum, tomus und pagina und die Namen bei beiden Eintragungen eines Brautpaares übereinstimmen, was aber oft nicht der Fall ist. Damit erfolgt auch in diesem Prozessschritt eine Bereinigung mancher Ungereimtheiten.
Ergänzung der Heider-Hochzeitsdaten mit überregionalen Informationen
In die FA-Hochzeitsdatenbank werden Daten von den unterschiedlichsten Quellen eingespeist. Die Daten der Heider-Register sind zwar ein wichtiger Teil davon, müssen aber von den Daten aus anderen Quellen unterschieden werden können. Im letzten Arbeitsschritt des Erfassungsprozesses werden daher den bisher erarbeiteten regionalen Hochzeitsdaten der Heider-Hochzeitsrgister noch überregionale Informationen wie Kronland, heutiger Name des Staates, Buchtyp und Quellenangaben hinzugefügt. Damit ist z.B. sichergestellt, dass beim Auffinden von verschiedenen Daten zum selben Brautpaar ersichtlich ist, von welcher Quelle die Informationen stammen.
Einspeisung in die DB
Sobald eine größere Anzahl von Daten vorhanden ist, werden diese im letzten Arbeitsschritt in die Datenbank eingespeist und stehen damit dem Benützer für Abfragen zur Verfügung.